




I. Analyser▲
I-A. Utilisation du Générateur de Profils▲
Le générateur de profils (profiler en anglais) permet de tracer les requêtes et divers événements se produisant sur le serveur SQL Server. Il constitue un outil indispensable et incontournable dont la bonne utilisation transforme la vie du DBA et du développeur. Nous allons en présenter l'utilisation pour optimiser son code.
I-A-1. Créer une trace▲
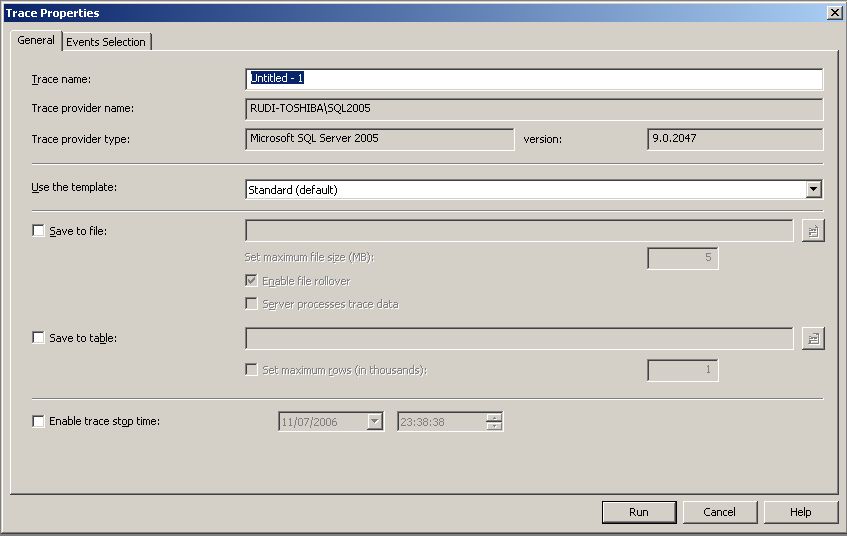
Après ouverture du profiler et création d'une nouvelle trace, l'écran ci-dessus apparaît.
Vous voyez ici que vous pouvez utiliser un template, qui vous fournira une configuration existante ou sauvegardée par vous auparavant. Vous pouvez sauvegarder le résultat de la trace dans un fichier ou une table de base de données. Si vous ne faites pas ce choix à cette étape, vous pourrez toujours effectuer cette sauvegarde sur votre trace arrêtée. Vous pouvez également indiquer une heure d'arrêt de la trace. C'est utile pour la faire tourner automatiquement, en exportant son script de création pour le créer sur le serveur et en planifier le lancement : dans le menu File/Fichier.

Le deuxième onglet de la fenêtre de création de trace vous permet de sélectionner les événements à recevoir.
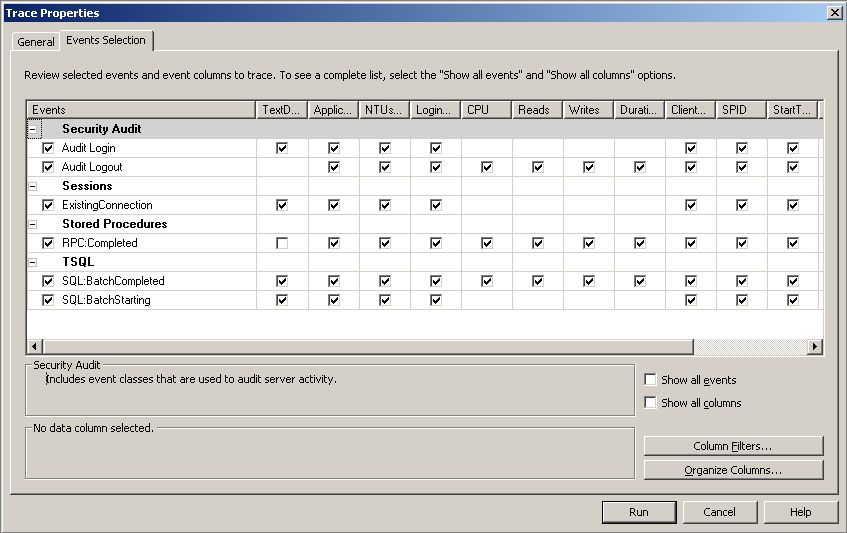
Vous voyez sur la copie d'écran les événements sélectionnés pour le template par défaut. Pour le sujet qui nous intéresse, les événements d'audit de sécurité sont inutiles, vous pouvez donc les enlever, ainsi que les connexions existantes, qui afficheront une suite de lignes au lancement de la session de profilage seulement.
I-A-2. Événements▲
Beaucoup d'événements sont à votre disposition. Vous pouvez les sélectionner en cochant « Show all events ». Voici une liste non exhaustive d'événements intéressants pour le profilage de performances :
| Événement | Description |
|---|---|
| Errors and Warning/ Exception | Vous permet de tracer les erreurs SQL provenant de votre code. |
| Locks/Locks:Timeout | Timeout d'attente sur les verrous, peut-être le signe d'une mauvaise stratégie de requêtage, notamment impliquant des transactions trop longues. |
| Stored Procedures/SP:Recompile | Trace les recompilations de procédures. La colonne Object Name contient le nom de la procédure. |
| Objects/Object:Created et Objects/Object:Deleted | En ajoutant ObjectType et ObjectName, et en filtrant par ObjectType 17, vous pouvez tracer la création et la suppression de tables temporaires. |
Voici un exemple de trace générée par le profiler :

Les colonnes contiennent, dans l'ordre :
- le type d'événement, ici la complétion d'un batch de commandes SQL ;
- le code SQL envoyé au serveur ;
- le login de l'utilisateur ;
- la durée de la requête en temps CPU (millisecondes) ;
- le nombre de pages lues par l'exécution de la requête ;
- le nombre de pages écrites ;
- la durée totale d'exécution en millisecondes ;
- le ClientProcessId, qui correspond à l'id du process de l'application sur la machine cliente (hostprocess dans sysprocesses) ;
- le SPID (System Server Process Id) : l'id de la connexion ouverte sur SQL Server.
I-A-3. Filtrage▲
Sur un serveur sollicité, l'affichage du profiler peut se remplir de milliers de lignes par seconde. Il est donc utile de filtrer les événements. Cliquez sur le bouton « Column Filters… »
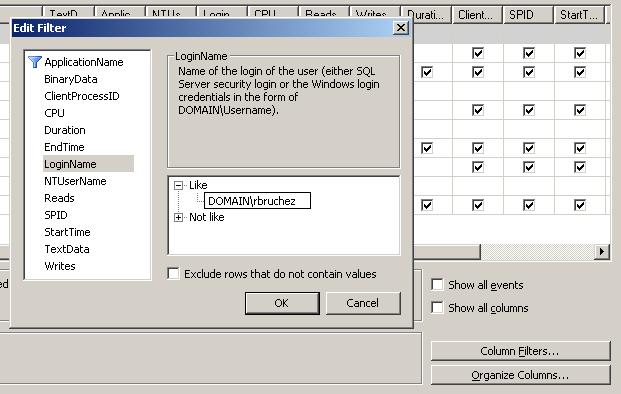
Vous voyez ici un filtre par nom de Login. Vous pouvez aussi filtrer par SPID, pour isoler une connexion (en sachant que le SPID est réattribué de connexion en connexion), par Hostname pour isoler une machine cliente, par ClientProcessId pour isoler une application cliente à travers toutes ses connexions ouvertes.
Le filtrage sur les colonnes numériques vous permet également de ne retourner que les requêtes ayant par exemple consommé plus d'un certain temps CPU, ou effectué un nombre minimum de reads. Cela se révèle très utile pour isoler les requêtes les plus coûteuses.
Nouveauté dans le profiler 2005 : la case à cocher « exclude rows that do not contain values », qui vous permet d'améliorer la pertinence de vos filtres. Dans le profiler 2000, les lignes dont la colonne filtrée a une valeur vide sont affichées quand même.
I-A-4. Groupement▲
Vous pouvez également grouper vos événements sur les colonnes de votre choix, ce qui vous permet de changer l'ordre d'affichage des événements et de les regrouper pour un même login, SPID, ou ClientProcessId…
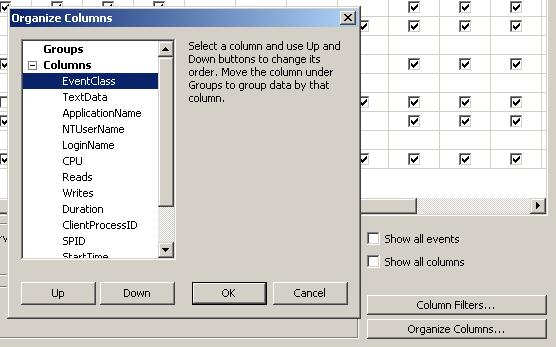
Ceci en cliquant sur le bouton « Organize Columns… »
I-A-5. Conclusion▲
Le profiler est un outil d'usage quotidien de première importance, qui vous permet à tout moment de vous rendre compte de la charge de votre serveur et d'isoler le code SQL le plus gourmand en ressources. Lorsque vous avez trouvé ces requêtes indésirables, vous pouvez en copier-coller l'appel dans SSMS pour analyser son plan d'exécution.
I-B. Lecture du plan d'exécution▲
Le plan d'exécution est le résultat auquel l'optimiseur arrive en analysant une requête, pour choisir son mode d'exécution optimal, à partir des données qui sont à sa disposition : structure des tables, présence d'index et de contraintes, statistiques de population des index et colonnes… Afficher et décrypter ce plan d'exécution vous permet d'affiner la qualité de vos requêtes et de corriger des problèmes de structure, notamment d'absence d'index, ou de présence d'index inutilisés.
Vous pouvez obtenir ce plan soit visuellement, soit en texte. Inutile de dire que la première version est bien plus conviviale au décryptage. Pour obtenir le plan d'exécution visuel dans SSMS (SQL Server Management Studio), vous avez un bouton de la barre d'outils SQL Editor ou clic droit sur la fenêtre d'édition de requête. Le plan d'exécution estimé de la requête sélectionnée peut être affiché avec un CTRL+L.
Dans SQL Server 2005, l'affichage du plan d'exécution graphique est généré par l'envoi au serveur d'un SET STATISTICS XML ON. En version 2000, c'est un SET STATISTICS PROFILE ON. Le retour de ces commandes est le plan d'exécution généré par l'optimiseur, plus le nombre réel d'exécutions de chaque étape, et le nombre de lignes retournées.
Pour obtenir le plan d'exécution texte :
| SET SHOWPLAN_TEXT ON ou SET SHOWPLAN_ALL ON |
Plan estimé. |
| SET STATISTICS PROFILE ON | Le même plan avec les nombres de lignes affectées, et le nombre d'exécutions de chaque opérateur. |
SQL Server 2005 ajoute des versions XML de ces commandes.
Chaque instruction du batch ou de la sélection sur laquelle vous affichez le plan d'exécution présente évidemment son propre plan d'exécution, vous aurez donc dans ce cas plusieurs plans l'un après l'autre. Dans ce cas, chaque plan se voit attribuer un pourcentage de charge relative à la totalité des instructions, nommé coût relatif.
Ce coût relatif est une information très utile qui vous permet de vous concenter rapidement sur les requêtes les plus coûteuses lorsque vous voulez analyser les performances d'un batch d'instructions, par exemple l'exécution d'une ou plusieurs procédures stockées appelées en séquence. Le pourcentage obtenu est une estimation prenant en compte les divers éléments du plan d'exécution à disposition. Il ne s'agit pas d'un rapport réel basé par exemple sur le temps CPU de chaque opération, puisque cette information n'est pas récupérée pour ce plan (rappelons que les informations du plan visuel sont basées sur un SET STATISTICS PROFILE ON).
Pour identifier rapidement les problèmes dans un plan d'exécution visuel, concentrez-vous sur trois éléments : les pourcentages de charge sur chaque opération, les scans de table, et l'épaisseur des flèches qui relient les opérations.
Le pourcentage de chaque opération est tout comme le pourcentage total de charge du plan, une estimation. Il vous indique toutefois de manière très fiable quelles opérations sont les plus coûteuses.
I-B-1. Le scan▲
Le scan de la table diffère du seek. Le scan est le parcours du contenu d'une table ou du dernier niveau d'un index. Une table étant physiquement une liste doublement liée (un pointeur sur l'enregistrement précédent, un pointeur sur l'enregistrement suivant), SQL Server choisit de parcourir chaque enregistrement et d'y tester le critère désiré (s'il y en a un). Si c'est pour trouver une ligne dans une table de dix mille enregistrements, il y a, à l'évidence, un problème d'optimisation. Si la table ne comporte aucun index, c'est le comportement obligatoire de SQL Server, il n'a pas d'autre choix.
Le seek représente le parcours d'un index. Un index est une structure arborescente balancée (b-tree).
Définition de b-tree empruntée à alaide.com :
Méthode de structuration pour le stockage et l'accès aux données. Elle consiste à diviser les possibilités de choix en deux parts égales et établir des pointeurs vers les deux sous-blocs. De cette façon, pour rechercher un élément, on le compare d'abord avec l'élément de la tête de l'arbre. Si l'élément recherché est celui-là, la recherche est terminée, sinon soit elle est plus grande, soit plus petite ; dans l'un ou l'autre cas on continue la recherche dans le sous-bloc correspondant en utilisant le pointeur approprié.
En d'autres termes, si un index est présent et comporte une ou plusieurs colonnes présentes dans le critère de recherche, l'optimiseur peut choisir d'utiliser l'index, donc de parcourir l'arbre pour atteindre le pointeur vers l'enregistrement de la base (en cas d'index non ordonné), au lieu de parcourir chaque enregistrement.
Dans le plan d'exécution visuel, le scan est différencié du seek par l'icône :
![]() Scan de table ;
Scan de table ;
![]() Scan d'index ;
Scan d'index ;
![]() Seek d'index.
Seek d'index.
Le scan de table n'intervient que sur une table de type heap (tas…), c'est-à-dire une table qui ne comporte pas d'index ordonné. Un index ordonné force la distribution physique des enregistrements. Un scan d'index ordonné équivaut donc à un scan de table, certes plus efficace lorsqu'on cherche dans la clé de l'index ordonné.
Vous pouvez utiliser la requête suivante (valable pour SQL Server 2005) pour savoir si vos tables comportent ou non un index ordonné :
SELECT t.name as tableName, i.type_desc as tableType
FROM sys.indexes i
JOIN sys.tables t ON i.object_Id = t.object_Id
WHERE i.index_id < 2
ORDER BY t.nameI-B-2. Les reads▲
Des statistiques complémentaires vous seront utiles pour juger des performances d'une requête. La principale est le nombre de pages lues par table présente dans la requête. Cette information vous est retournée par SET STATISTICS IO ON.
Exemple de retour de statistiques IO :
Table 'sysidxstats'. Scan count 6, logical reads 12, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.Sur chaque ligne de ces statistiques, vous obtenez le nom de la table, le nombre de scans effectués sur la table, et les nombres de lectures. Pour vos besoins d'optimisation, les lectures logiques vous donnent l'information dont vous avez besoin.
L'unité ici est la page. La page SQL Server est l'unité de base et en même temps l'unité maximale de stockage d'un enregistrement (avec quelques exceptions en SQL Server 2005 notamment pour les colonnes de type varchar). Elle est dimensionnée à 8 ko. Une page peut contenir plusieurs enregistrements, mais un enregistrement ne peut pas être contenu dans plus d'une page, ce qui limite concrètement la taille de vos enregistrements à 8060 octets (les blobs text et images sont stockés de façon différente, et SQL Server 2005 offre un mécanisme pour s'affranchir de cette limite pour les colonnes de type (n)varchar et varbinary). Lorsque le moteur de stockage de SQL Server lit des enregistrements sur le disque ou en cache, il lit des pages.
La lecture sur disque est l'opération la plus coûteuse d'une requête, il est donc important de limiter le nombre de pages lues, en s'assurant d'avoir assez de RAM pour permettre à SQL Server de stocker les pages les plus fréquemment accédées dans son cache, et plus important, en limitant le nombre de pages lues par la création d'index ou l'optimisation du code SQL.
Les lectures logiques affichées par SET STATISTICS IO ON vous indiquent le nombre total de pages lues sur chaque table impliquée dans la requête. Concentrez-vous sur les nombres les plus élevés, observez les parties du plan d'exécution qui affichent les opérations sur ces tables, et si vous y voyez des scans, réfléchissez à la possibilité de créer un index.
I-B-3. Les flèches▲
Les flèches qui relient les différentes opérations représentent le flux de l'information extraite du moteur de stockage et traité pour obtenir le résultat de la requête. Ce flux se lit de droite à gauche, le résultat final de la requête se trouvant en haut à gauche du graphique. L'épaisseur des flèches vous permet en un coup d'œil de déterminer les opérations les plus coûteuses. Plus la flèche est épaisse, plus l'opération d'où elle provient a retourné de lignes. Considérez l'exemple ci-dessous :
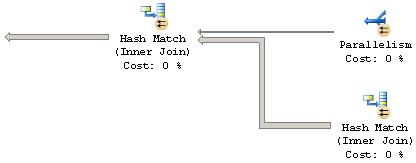
Vous pouvez voir que la flèche du bas est bien plus épaisse que celle du haut. Simplement parce que l'opération du bas (le Hash Join de droite) retourne 56 000 lignes, alors que la parallélisation du haut traite 26 lignes. Concentrez-vous sur les sources de flèches les plus grosses en priorité pour améliorer les performances de votre requête.
I-C. Obtenir d'autres statistiques▲
Vous pouvez utiliser SET STATISTICS TIME ON devant votre requête pour obtenir les statistiques de temps d'exécution, en termes de temps CPU et de temps total. Le temps CPU peut vous donner une indication supplémentaire de la charge que votre requête fait subir au serveur. Le temps total vous indique, en regard du temps CPU, combien de temps a été utilisé à attendre sur des locks, ou à transmettre les résultats.
Pour obtenir les statistiques constantes de l'exécution d'une instruction, vous avez deux commandes à votre disposition qui vous permettent, pour l'une de vider le cache de procédure (qui conserve le plan d'exécution optimisé des procédures stockées et des requêtes ad hoc) :
DBCC FREEPROCCACHEet pour l'autre, de vider le cache de données propres :
DBCC DROPCLEANBUFFERSc'est-à-dire les données en cache qui ont déjà été écrites sur le disque.
Après l'exécution de ces deux commandes, votre code sera recompilé et les pages de données seront lues sur le disque.
N'utilisez pas ces commandes sur un serveur de production, à moins de vouloir faire une farce à votre équipe de support.
I-D. Performance Monitor▲
Perfmon est l'outil de monitoring de Windows. À l'installation de SQL Server, des indicateurs sont ajoutés, qui permettent de surveiller l'activité du serveur SQL. Nous allons en présenter les principaux pour obtenir une bonne idée de l'état de santé de votre instance SQL.
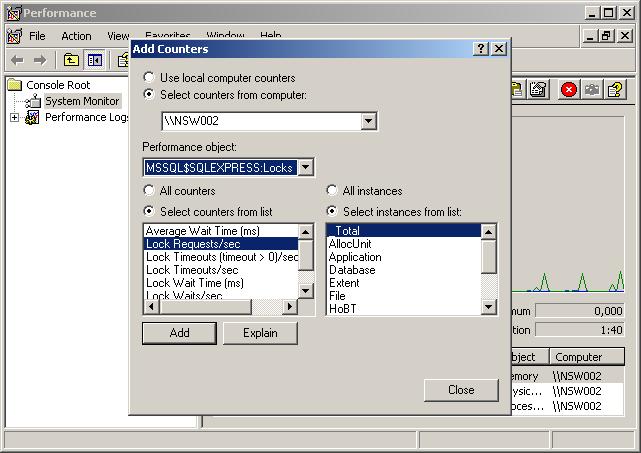
La situation idéale de monitoring dans mon expérience a été la mise à disposition de deux écrans. Ainsi, sur le deuxième écran, j'ai toujours visible l'état du serveur. J'ai créé deux fenêtres du Performance Monitor, l'une avec les CPU individuels, et la moyenne des CPU en gras (les indicateurs sont dans processor\% Processor Time). Pour diminuer la charge du serveur, j'ai baissé la fréquence de récupération d'infos à trois secondes. Cette fenêtre s'affiche en graphe.
Dans l'autre fenêtre, j'affiche les indicateurs de mémoire et de disque, en l'occurrence :
LogicalDisk
% Disk Read Time
% Disk Write Time
Avg. Disk Queue Length
Memory
Cache Faults/sec
SQLServer:Buffer Manager
Buffer cache hit ratio
Page Reads/secLe Avg. Disk Queue Length est un bon indicateur pour déterminer si les IO physiques (donc le disque) sont réellement un goulot d'étranglement. Si cet indicateur est constamment élevé, vous avez un problème. Le regarder avec le Buffer cache hit ratio vous donne une bonne idée de la source du problème : disque physique ou RAM. Pour lancer facilement les deux fenêtres en un seul clic, voici l'exemple d'un script WSH :
Option Explicit
Dim oWsh : Set oWsh = CreateObject("WScript.Shell")
oWsh.Run "mmc ""C:\mypath\CPU.msc"""
oWsh.Run "mmc ""C:\mypath\SQL MEMORY AND DISK.msc"""
Set oWsh = NothingI-D-1. Identification des connexions▲
Soudainement, vous voyez le ou les CPU de votre serveur monter en flèche. Vous lancez une session de Profiler, et malgré cela vous n'arrivez pas à identifier la source de la surcharge. Vous pouvez. Grâce au Performance Monitor, identifier quelle connexion utilise le processeur intensivement. Comme c'est une opération qui prend un peu de temps, elle est surtout utile pour une connexion qui se conduit mal pendant au moins plusieurs minutes. Sélectionnez, dans les indicateurs de Threads, les instances sqlservr/# pour les compteurs % Processor Time et ID Thread. Vous risquez malheureusement d'en avoir beaucoup sur un serveur de production.
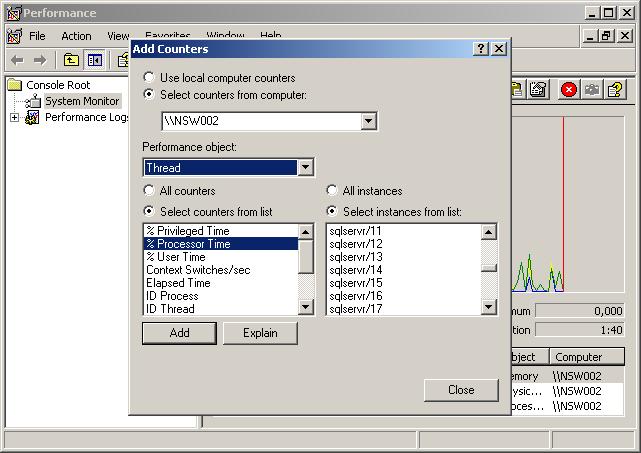
Affichez ensuite le résultat sous forme de rapport (CTRL+R) afin d'améliorer la lisibilité.

Si vous identifiez un processus qui maintient un pourcentage élevé de CPU, notez son ID Thread. Il correspond à la colonne kpid de la table système sysprocesses de la base master de SQL Server 2000, ou de la vue système sys.sysprocesses dans SQL Server 2005. Voici un exemple de requête pour obtenir les informations de processus :
SELECT blocked, lastwaittype, waittime, DB_NAME(dbid) as db, hostname, loginame, cmd, last_batch, cpu
FROM master.sys.sysprocesses
WHERE kpid = 1792II. Résoudre▲
Après avoir parcouru les outils permettant d'identifier les problèmes, comment faire pour les résoudre ? C'est encore un domaine complexe, nous allons simplement nous concentrer sur les réponses évidentes.
II-A. Index▲
Les index sont indispensables sur les tables de plus de quelques enregistrements. Pour autant, ils ne doivent pas être créés légèrement. Indexer toutes les colonnes d'une table par simple principe de précaution est une erreur qui vous coûtera en performances (et en espace disque). En effet, chaque index ralentit les opérations d'insertion et de modification de données, et c'est logique : l'index doit être maintenu. Mais que cela ne vous fasse pas peur pour créer vos index nécessaires. SQL server est très performant pour maintenir ses index.
Comment savoir quel index créer, quelle colonne indexer ? Lorsque vous avez regardé le plan d'exécution d'une requête, vous avez identifié les tables qui sont scannées, et celles qui retournent beaucoup d'enregistrements. Vous devez naturellement vous concentrer sur celles-là.
Il existe un assistant qui peut vous rendre de grands services pour l'indexation de vos tables, il s'agit du Database Engine Tuning Advisor, présent dans le menu Tools de SSMS (SQL Server Management Studio). Il était appelé Index Tuning Wizard dans SQL Server 2000. Cet outil analyse vos requêtes (un batch sélectionné dans votre fenêtre d'édition, ou le résultat d'une trace réalisée avec le profiler) pour vous suggérer la création d'index, et ajoute ces index pour vous si vous le souhaitez. Comme cet article est destiné à vous donner des notions d'optimisation, nous utiliserons plutôt ici notre cerveau. Mais même ainsi, il est très utile de lancer après coup le DETA pour comparer les résultats ou voir s'il a d'autres suggestions à nous faire.
En laissant votre souris sur une opération de scan du plan d'exécution, ou en affichant la fenêtre de propriétés, vous verrez la liste de prédicats de recherche, ainsi que la liste des colonnes retournées. La liste des prédicats va vous donner les colonnes à indexer. Attention, toutes les colonnes ne sont pas des candidates égales à l'indexation, parce que même si un index existe sur une colonne, SQL Server ne va pas forcément l'utiliser dans une recherche.
La création d'un index s'accompagne de la création de statistiques de distribution des données de la colonne. En d'autres termes, SQL Server conserve des statistiques de remplissage des valeurs de la colonne, afin d'estimer combien d'enregistrements va retourner une requête comportant une clause de recherche sur cette colonne. Si le nombre d'enregistrements à retourner est trop important par rapport au nombre total d'enregistrements de la table, SQL server choisira probablement le scan, estimant qu'il est moins coûteux de parcourir la table une fois que de parcourir de multiples fois l'arbre de l'index. C'est particulièrement vrai pour un index non ordonné, où il faut ajouter le coût du bookmark lookup.
La commande DBCC SHOW_STATISTICS ('NomdeTable', 'NomdIndex') vous permet de voir les statistiques maintenues sur un index. Le chiffre intéressant à voir dans les résultats de cette commande est la densité. La densité représente un ratio des valeurs identiques dans la colonne. Plus la densité est élevée, moins la sélectivité de l'index l'est, et moins l'index est intéressant. Par exemple, créer un index sur une colonne de type bit (valeurs possibles : 1, 0, NULL) n'est intéressant que s'il y a peu d'occurrences d'une des deux valeurs (0 ou 1), et qu'on cherche justement les enregistrements qui ont cette valeur. Sinon, l'index ne sera très certainement pas utilisé.
II-A-1. Couverture▲
Pour certaines requêtes qui retournent peu de colonnes, la technique de l'index couvrant (covering index) peut améliorer très nettement les performances, en évitant l'opération lourde du bookmark lookup. Couvrir une requête, c'est créer un index non ordonné dont la clé est composée de toutes les colonnes retournées par la requête, en plaçant bien sûr les colonnes cherchées par la clause WHERE en premier. Voici un exemple en trois temps, d'un SELECT sur une table de la base de démonstration de Microsoft : AdventureWorks. Comparons les plans d'exécution d'une même requête :
SELECT CarrierTrackingNumber, UnitPrice
FROM Sales.SalesOrderDetail
WHERE UnitPrice = 5.7Ce qui doit retourner 210 lignes sur un total de 121 317.
Premièrement, en laissant les index par défaut sur la table :

Vous noterez que, à cause de l'absence d'index sur la colonne UnitPrice, l'optimiseur est obligé de choisir un scan de la table. Donc, créons un index sur cette colonne :
CREATE NONCLUSTERED INDEX nix$Sales_SalesOrderDetail$UnitPrice
ON Sales.SalesOrderDetail (UnitPrice)Notons au passage que cette opération est aussi traitée par l'optimiseur, à son propre plan d'exécution :

Remarquez l'épaisseur des flèches. 121 317 lignes sont à traiter.
Lançons ensuite la même requête :
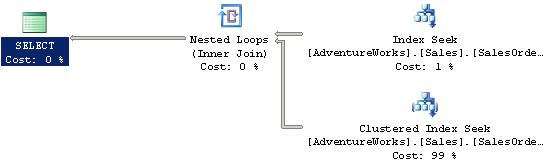
Ici, une forme de bookmark lookup adaptée aux tables comportant un index ordonné. SQL server 2005 choisit de parcourir l'index ordonné pour chaque ligne trouvée depuis l'index que nous venons de créer. Chaque enregistrement trouvé dans l'index est recherché dans la table par l'index ordonné. Cela provoque donc 210 parcours de l'index ordonné.
Modifions notre index pour couvrir les besoins de la requête :
DROP INDEX Sales.SalesOrderDetail.nix$Sales_SalesOrderDetail$UnitPrice
GO
CREATE NONCLUSTERED INDEX nix$Sales_SalesOrderDetail$UnitPrice_CarrierTrackingNumber
ON Sales.SalesOrderDetail (UnitPrice, CarrierTrackingNumber)
GORéexécutons :

Ici toutes les colonnes de la requête ont pu être servies par l'index. SQL server n'a aucun besoin d'aller chercher des informations supplémentaires dans la table.
II-B. Recompilation▲
Un élément parfois caché qui peut diminuer vos performances est la recompilation en milieu d'exécution d'une procédure stockée. Pourquoi diable une procédure se recompilerait-elle, et comment lui taper sur les doigts ?
Il ne faut pas : elle a bien raison. Une procédure se recompile lorsque les conditions de sa première compilation changent. Cela peut arriver de plusieurs façons, le plus couramment lorsqu'une table temporaire est créée dans la procédure, et que sa structure est modifiée ou que le nombre de ses enregistrements change significativement, ou lorsque vous changez à l'intérieur de la procédure certains settings de la connexion, par exemple le format de date à l'aide de SET DATETIME.
Pour tracer les éventuelles recompilations grâce au profiler, utilisez les événements de Stored Procedure suivants : SP:Recompile, SP:Starting, SP:Completed. En y ajoutant SP:StmtStarting et SP:StmtCompleted, vous pourrez tracer plus finement quelle instruction dans la procédure stockée a déclenché la recompilation : le SP:Recompile se trouvera entre SP:StmtStarting et le SP:StmtCompleted correspondant.
Depuis le service pack 2 de SQL Server 2000, l'événement SP:Recompile retourne la raison de la recompilation dans la colonne EventSubClass. Les valeurs retournées sont expliquées dans cet article. Pour éviter ces recompilations, ou en diminuer les effets, suivez ces quelques règles :
- préfixez tous vos objets par dbo. dans SQL Server 2000. Cela évitera à SQL server de poser des locks de compilation au lancement de la procédure pour déterminer si les objets contenus dans la procédure ont le même propriétaire que la procédure stockée ;
- évitez de modifier les options de la connexion à l'intérieur de la procédure, telles que les SET ANSI…, SET DATETIME…
- utilisez (parcimonieusement !) l'option de requête KEEPFIXED PLAN pour éviter les recompilations dues à des mises à jour de statistiques ;
- essayez autant que possible de vous passer des tables temporaires.
II-C. Statistiques▲
Nous l'avons vu, l'optimiseur se base sur des statistiques de distribution pour juger de la stratégie à adopter. Par défaut, SQL Server maintient automatiquement ses statistiques, en le créant au besoin, et en les recalculant lorsqu'un nombre significatif de lignes de la table a été modifié. Si vous désirez vous assurer que les statistiques sont présentes, ouvrez les propriétés de votre base de données, et regardez la valeur de Auto Create Statistics et Auto Update Statistics.
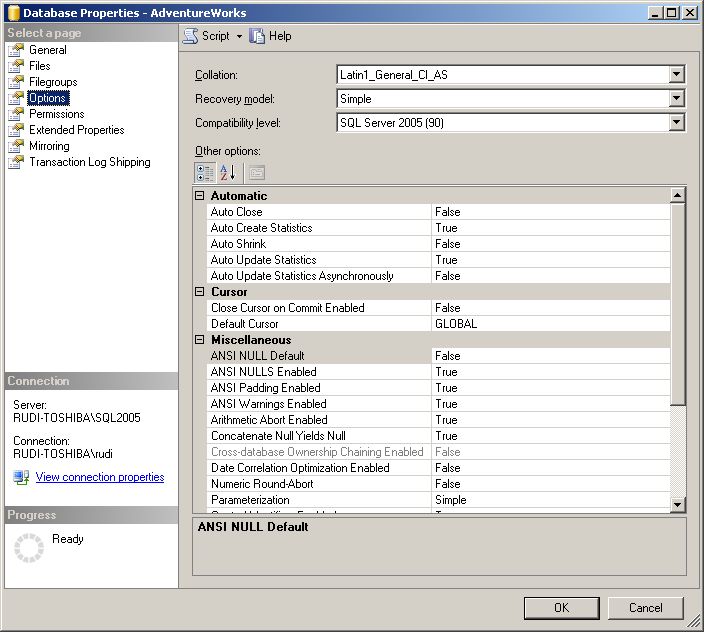
Une autre façon de tracer l'absence de statistiques est d'utiliser le Profiler, événement Errors and Warnings/Missing Column Statistics. Vous le voyez également le warning dans un plan d'exécution visuel, et un clic droit sur l'icône vous permet de créer les statistiques manquantes.
II-D. Éléments de requêtes▲
II-D-1. Fonctions▲
Une erreur commune, qui peut affecter fortement les performances, est d'écrire du code SQL avec la même approche intellectuelle que pour l'écriture de code procédural. Par exemple, en encapsulant une partie de la logique d'un SELECT dans une fonction (UDF, ou User Defined Function).
Comme nous l'avons vu, le plan d'exécution d'une requête SQL est optimisé à l'aide des informations que le moteur SQL détient sur le système et la structure des données. Sachant cela, il est important en écrivant son code de faciliter le travail de l'optimiseur pour qu'il puisse créer le meilleur plan d'exécution possible.
Par exemple, dans un SELECT, en déplaçant une partie des tables recherchées dans une fonction, on enlève à l'optimiseur la possibilité de comprendre les relations entre les tables. On oblige donc l'optimiseur à passer dans la fonction pour chaque ligne retournée par le SELECT, ce qui se révèle très contre-productif.
Prenons un exemple simple, à l'aide des tables d'AdventureWorks. Pour obtenir le total des taxes payées par territoire, la requête suivante remplit parfaitement son office :
SELECT st.Name as Territory, SUM(soh.TaxAmt) as TaxAmt
FROM Sales.SalesOrderHeader soh
JOIN Sales.SalesTerritory st ON soh.TerritoryID = st.TerritoryID
GROUP BY st.Name
ORDER BY st.NamePas très sophistiqué n'est-ce pas ? Pourquoi ne pas encapsuler cette recherche de total dans une fonction que nous pourrons réutiliser ?
CREATE FUNCTION Sales.GetTaxAmtPerTerritory (@TerritoryID int)
RETURNS money
AS BEGIN
DECLARE @TaxAmt money
SELECT @TaxAmt = SUM(TaxAmt)
FROM Sales.SalesOrderHeader
WHERE TerritoryID = @TerritoryID
RETURN @TaxAmt
ENDC'est le bonheur, nous avons rempli notre devoir de programmeur en faisant du code réutilisable. Relançons notre requête :
SELECT st.Name as Territory, Sales.GetTaxAmtPerTerritory (st.TerritoryID) as TaxAmt
FROM Sales.SalesTerritory st
ORDER BY st.NameSi l'idée nous prend de comparer les performances des deux requêtes, voici ce que nous obtenons :
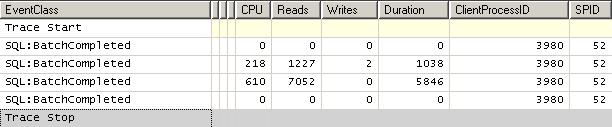
La première version (SUM et JOIN) dure une seconde et effectue 1227 lectures de pages. La seconde 7052 lectures de pages en un peu moins de six secondes. CQFD.
II-D-2. Verrous et niveau d'isolation▲
Une requête de type SELECT pour des verrous partagés (shared locks) sur les données lues. Ces verrous partagés permettent de garantir le niveau d'isolation par défaut de la transaction qui est READ COMMITTED. En français, cela veut dire que lorsque vous lisez un enregistrement, vous avez la garantie qu'il est propre, et que personne n'essaie de la modifier au même moment. Il existe cinq (quatre dans SQL server 2000) niveaux d'isolation. Deux sont plus contraignants que l'isolation par défaut, et deux moins contraignants.
Vous pouvez baisser le niveau d'isolation pour permettre la lecture d'enregistrements « sales » (dirty reads), c'est-à-dire de lignes qui sont potentiellement en modification, qui font partie d'une transaction non encore terminée, ou qui sont en cours de rollback. Vous prenez de ce fait le risque d'obtenir des données erronées. En contrepartie, baisser votre niveau d'isolation vous permet d'augmenter les accès concurrentiels et dans certains cas d'augmenter les performances de traitement sur des serveurs très sollicités. Le niveau d'isolation permettant les dirty reads s'appelle READ UNCOMMITTED.
En READ UNCOMMITTED, une requête SELECT n'honore pas les verrous posés sur les enregistrements lus, et à son tour ne pose pas de verrous partagés. En me répétant, cela augmente les performances mais diminue la fiabilité de vos lectures de données. Utilisez donc ce niveau d'isolation en sachant ce que vous faites.
Pour indiquer à SQL server d'utiliser le niveau d'isolation READ UNCOMMITTED, vous pouvez soit modifier le niveau d'isolation de la connexion :
SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTEDEn le remettant dans l'état où vous l'avez trouvé à la fin de votre code (notamment dans une procédure stockée) :
SET TRANSACTION ISOLATION LEVEL READ COMMITTEDVous pouvez aussi le spécifier dans votre requête pour une table en particulier :
SELECT st.Name as Territory, SUM(soh.TaxAmt) as TaxAmt
FROM Sales.SalesOrderHeader soh WITH (READUNCOMMITTED)
JOIN Sales.SalesTerritory st ON soh.TerritoryID = st.TerritoryID
GROUP BY st.Name
ORDER BY st.NameLe mot-clé READUNCOMMITTED est un synonyme de NOLOCK. Vous verrez sans doute plus souvent WITH (NOLOCK). READUNCOMMITTED est simplement SQL ANSI, NOLOCK est un mot-clé T-SQL. Les effets sont strictement identiques.
SQL Server 2005 introduit un niveau d'isolation plus concurrentiel encore, appelé SNAPSHOT. Basé sur une technologie de version de ligne (row versioning), il nécessite que l'option ALLOW_SNAPSHOT_ISOLATION de votre base de données soit à ON. Pour faire simple, une copie des données est stockée dans une table temporaire de tempdb, avec une information de version. Lorsque vous lisez les données dans ce niveau d'isolation, cette version des lignes est créée et utilisée, et aucun verrou n'est posé sur la table originale. De plus, la lecture dans une transaction de niveau SNAPSHOT est consistante avec l'état des données au moment de la création de cette transaction. En interne, SQL server conserve une version des données au moment de la création de votre transaction.
Si vous modifiez des données dans ce niveau d'isolation, SQL Server adopte un mode de verrouillage optimiste, et les lignes à modifier ne seront verrouillées qu'au moment de la modification. À ce moment, si les lignes ont été modifiées entre temps (SQL server le sait, toujours grâce à son mécanisme de row-versioning), votre transaction sera automatiquement annulée (donc votre mise à jour). Il est donc plus prudent de limiter l'utilisation de ce niveau d'isolation à la lecture de données.
III. Conclusion▲
Les éléments présentés ici ne sont en rien exhaustifs, et ils représentent une compilation de concepts et d'outils dont il vous est libre d'approfondir l'usage. Pour une compréhension plus poussée des concepts énoncés ici, je vous recommande la lecture des livres de Sajal Dam (SQL Server Query Performance Tuning Distilled), de Kalen Delaney et de Ken Henderson.