




I. Introduction▲
Dans cet article nous allons détailler l'utilité et le fonctionnement des statistiques de distribution, présentes sur les index et les colonnes.
Ces statistiques sont indispensables aux bonnes performances de l'exécution des requêtes et leur nature est parfois mal connue.
II. Utilité des statistiques▲
Prenons un exemple.
Vous avez fait la connaissance sur un chat internet d'une jeune fille qui vous semble charmante et qui vit à Courtrai, en Belgique flamande. Elle semble apprécier vos grandes qualités de cœur et vous convenez d'un premier rendez-vous, afin de vous connaître en vrai. Comme vous êtes galant, vous proposez de faire le voyage à Courtrai. Elle vous donne rendez-vous au café De Brouwzaele.
Si vous n'avez jamais entendu parler de Courtrai, vous ne savez probablement rien de la taille de la ville, de la complexité de ses rues et donc vous ne pouvez par juger, avant de vous y rendre, si vous trouverez le café De Brouwzaele facilement.
Logiquement, votre premier réflexe sera de vous renseigner sur le nombre d'habitants. Si Courtrai est une ville de quelques milliers d'âmes, vous pouvez vous dire qu'elle est peu étendue et que le café De Brouwzaele sera facile à trouver. Par contre, en cherchant sur Wikipédia, vous vous apercevez que Courtrai compte quelque 73 000 habitants. Sachant cela, vous vous attendez à plus de difficultés. Vous allez donc demander l'adresse du café De Brouwzaele. Kapucijnestraat 19… bien, mais, combien y a-t-il de rues à Courtrai, et où se trouve Kapucijnestraat par rapport à la gare ? La connaissance de ces détails risque d'influencer fortement votre méthode de déplacement.
Pour SQL Server, la problématique est exactement la même. Imaginons que nous envoyons cette requête dans la base d'exemple AdventureWorks :
SELECT *
FROM Production.TransactionHistory
WHERE ProductId = 800La première chose que sait SQL Server, c'est qu'il y a 113 443 lignes dans la table Production.TransactionHistory (dans ce cas, il maintient un row count dans la définition des index). Ensuite, il sait qu'il dispose d'un index sur la colonne ProductId, qui va lui permettre de filtrer rapidement les enregistrements où ProductId = 800 :
SELECT *
FROM sys.indexes i
WHERE OBJECT_NAME(i.object_id)L'index s'appelle IX_TransactionHistory_ProductId.
L'optimiseur de SQL Server se base sur l'évaluation du coût d'un plan d'exécution afin de déterminer la meilleure stratégie. C'est ce qu'on appelle une optimisation basée sur le coût (cost-based optimization).
Mais pour évaluer le coût d'un plan d'exécution, SQL Server ne peut se contenter des seules informations que nous venons de voir. Il doit disposer d'une estimation du nombre de lignes qui vont être retournées, pour juger au plus juste du coût de celle-ci. C'est là où interviennent les statistiques.
Si SQL Server dispose de statistiques de distribution des valeurs contenues dans une colonne, il peut évaluer avec une bonne précision le nombre de lignes impactées lorsqu'une requête filtre sur ces valeurs, car il sait à l'avance combien de lignes environ correspondent au critère.
Les statistiques sont donc un échantillonnage des données. Elles sont créées et maintenues automatiquement par SQL Server sur la clé de tout index créé.
Jetons un premier coup d'œil sur les statistiques de l'index sur ProductId.
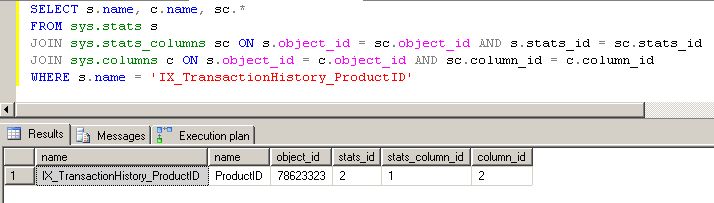
Où nous voyons que des statistiques existent dans cet index, pour la colonne ProductId.
Elles sont en quelque sorte les informations vitales de l'index, ou son diplôme : elles permettent à SQL Server, dans sa stratégie, d'estimer le coût d'utilisation de l'index. En d'autres termes, grâce aux statistiques, SQL Server va pouvoir connaître à l'avance, approximativement, le résultat d'un
SELECT COUNT(*)
FROM Production.TransactionHistory
WHERE ProductId = 800Si le ratio entre le nombre de lignes qui répond au critère recherché et le nombre total de lignes est faible, SQL Server va choisir d'utiliser l'index. Si par contre il est important, et qu'une bonne partie des lignes de la table doit être retournée par la requête, SQL Server va certainement faire le choix de parcourir la table plutôt qu'utiliser l'index, parce qu'il sera moins coûteux de procéder de cette façon que de résoudre ligne par ligne les adresses de pointeurs contenues dans le dernier niveau de l'index.
II-A. Sur les index▲
Dans le cas qui nous occupe, ProductId = 800 correspond à 416 lignes/133 443. Voyons le plan d'exécution estimé :
DBCC FREEPROCCACHE
GO
SET SHOWPLAN_XML ON
GO
SELECT *
FROM Production.TransactionHistory
WHERE ProductId = 800
GO
SET SHOWPLAN_XML OFF
GOCi-dessous un extrait de ce plan :
<RelOp NodeId="0" PhysicalOp="Clustered Index Scan"
LogicalOp="Clustered Index Scan" EstimateRows="418"
EstimateIO="0.586088" EstimateCPU="0.124944" AvgRowSize="54"
EstimatedTotalSubtreeCost="0.711032" Parallel="0" EstimateRebinds="0"
EstimateRewinds="0">Nous voyons que l'optimiseur choisit de parcourir la table (donc ici un scan de l'index ordonné, puisque le dernier niveau de l'index ordonné correspond aux données de la table) au lieu d'utiliser l'index. Nous voyons aussi dans l'attribut EstimateRows que les statistiques permettent à l'optimiseur d'avoir une idée assez précise du nombre de lignes correspondant à la clause WHERE.
Essayons maintenant d'indiquer un nombre plus petit de lignes à retourner :
SELECT ProductId, COUNT(*)
FROM Production.TransactionHistory
GROUP BY ProductIdNous voyons par exemple que le ProductId 760 ne se retrouve que six fois dans la table. Essayons avec cela :
DBCC FREEPROCCACHE
GO
SET SHOWPLAN_XML ON
GO
SELECT *
FROM Production.TransactionHistory
WHERE ProductId = 760
GO
SET SHOWPLAN_XML OFF
GOUn extrait du plan d'exécution estimé :
<RelOp NodeId="2" PhysicalOp="Index Seek" LogicalOp="Index Seek"
EstimateRows="5.28571" EstimateIO="0.003125" EstimateCPU="0.000162814"
AvgRowSize="15" EstimatedTotalSubtreeCost="0.00328781" Parallel="0"
EstimateRebinds="0" EstimateRewinds="0">
...
<Object Database="[AdventureWorks]" Schema="[Production]"
Table="[TransactionHistory]" Index="[IX_TransactionHistory_ProductID]" />Cette fois-ci nous voyons que l'index est utilisé : c'est la solution la moins coûteuse. L'estimation des lignes à retourner, basée sur les statistiques de distribution, donne 5.28571 lignes. Nous verrons plus loin d'où SQL Server tire cette approximation.
II-B. Colonnes non indexées▲
Les statistiques sont-elles utiles uniquement pour les index ?
Non.
L'optimiseur peut profiter de la présence de statistiques même sur des colonnes qui ne font pas partie de la clé d'un index. Cela permettra à SQL Server d'évaluer le nombre de lignes retournées dans une requête qui filtre sur les valeurs de cette colonne, et donc de choisir un bon plan d'exécution. Par exemple, si la colonne participe à un JOIN, cela permettra à l'optimiseur de choisir le type de jointure le plus adapté.
En SQL Server 2000, comme les statistiques de colonne sont stockées dans la table système sysindexes avec la définition des index, la création de statistiques avait comme conséquence de diminuer le nombre possible d'index pouvant être créés sur la table.
Vous étiez limités à 249 index non ordonnés par table, donc à 249 index plus statistiques.
Sur des tables contenant beaucoup de colonnes, la création automatique des statistiques pouvait vous faire atteindre cette limite. Il vous fallait alors supprimer des statistiques (avec la commande DROP STATISTICS ) pour permettre la création de nouveaux index.
Dans SQL Server 2005, la limite du nombre de statistiques de colonne sur une table a été augmentée à 2000, plus 249 statistiques d'index, poussant le nombre de statistiques possibles sur une table à 2249.
Pour voir les statistiques créées automatiquement :
SELECT * FROM sys.stats WHERE auto_created = 1leurs noms commencent par _WA_Sys_.
II-C. Sélectivité et densité▲
Ces statistiques de distribution permettent de déterminer la sélectivité d'un index. Plus le nombre de données uniques présentes dans la colonne est élevé, plus l'index est dit sélectif. La plus haute sélectivité est donnée par un index unique, où toutes les valeurs sont distinctes, et les plus basses sélectivités sont amenées par des colonnes qui contiennent beaucoup de doublons, comme les colonnes de type bit, ou char(1) avec seulement quelques valeurs (par exemple H et F pour une colonne de type sexe).
À l'inverse, la densité représente le nombre de valeurs dupliquées présentes dans la colonne. Plus il y a de valeurs dupliquées, plus la densité est élevée.
Sur l'index dans son entier, le pourcentage moyen de lignes dupliquées donne la sélectivité et la densité : plus ce pourcentage est faible, plus l'index est sélectif, et plus il est élevé, plus l'index est dense. La densité s'oppose donc à la sélectivité.
III. Où se trouvent-elles▲
J'ai quelquefois entendu des imprécisions au sujet des statistiques. Les statistiques ne sont pas des index, et ne sont pas stockés comme les index ou dans les pages d'index. Notamment les informations de distribution ne se situent pas au niveau des nœuds de l'arborescence de l'index. Si c'était le cas, le plan d'exécution ne pourrait pas faire le choix d'utiliser l'index ou non… avant de l'utiliser, puisqu'il devrait entrer dans l'arborescence pour retrouver l'estimation de lignes à retourner, ensuite quitter l'index pour faire un scan si ce choix lui paraît meilleur.
Ce genre de décision doit se prendre avant de commencer le processus de recherche des données.
Ainsi, les données de statistiques sont disponibles en tant que métadonnées de l'index, et non pas dans sa structure propre. Elles sont stockées dans une colonne de type LOB (objet de grande taille), dans la table système sysindexes.
En faisant cette requête :
SELECT statblob
FROM sys.sysindexesOn peut voir que la colonne statblob, qui contient ces informations de statistiques, retourne NULL. La colonne contient bien des données, mais elles ne sont pas visibles par ce moyen, et la valeur retournée par requête sera toujours NULL. D'ailleurs,
SELECT *
FROM sys.indexesqui est la vue de catalogue affichant les données d'index, ne retourne pas cette colonne.
La seule façon de retourner les données de statistiques est d'utiliser une commande DBCC :
DBCC SHOW_STATISTICSou d'afficher les propriétés des statistiques dans l'explorateur d'objets de SQL Server Management Studio (nœud Statistiques), page Détails, qui affiche les résultats du DBCC SHOW_STATISTICS dans une zone de texte.
Exemple avec notre index :
DBCC SHOW_STATISTICS ( 'Production.TransactionHistory', X_TransactionHistory_ProductID)qui retourne un entête, la densité par colonne de l'index, et un histogramme de distribution des données, selon l'échantillonnage opéré :
III-A. Entête▲
| Name | Updated | Rows | Rows Sampled | Steps | Density | Average key length | String Index |
|---|---|---|---|---|---|---|---|
| IX_TransactionHistory_ProductID | Apr 26 2006 11:45AM | 113443 | 113443 | 200 | 0,01581469 | 8 | NO |
Vous trouvez dans l'entête les informations générales des statistiques : nom, date de dernière mise à jour, nombre de lignes dans l'index et nombre de lignes échantillonnées, nombre d'étapes (steps) effectuées pour effectuer cet échantillonnage, densité de l'index, longueur moyenne de la clé de l'index. Le booléen String Index indique si la colonne contient des résumés de chaîne, qui est une fonctionnalité de SQL Server 2005 que nous détaillerons plus loin.
III-B. Densité▲
| All density | Average Length | Columns |
|---|---|---|
| 0,0022675736961 | 4 | ProductID |
| 8,815E-06 | 8 | ProductID, TransactionID |
Le deuxième résultat vous indique la densité de chaque colonne de l'index. La clé de l'index dépendant toujours de la première colonne, la densité individuelle est calculée seulement pour celle-ci, ensuite les densités calculées sont celles des colonnes agrégées dans l'ordre de leur présence dans l'index (le préfixe de la clé), une colonne après l'autre, si l'index est composite, ou si l'index est non ordonné et présent sur une table ordonnée. Dans ce cas, comme nous le voyons ici, chaque index non ordonné contiendra la ou les colonnes de l'index ordonné en dernière position.
La densité est donnée par le nombre moyen de lignes pour une valeur de la colonne divisé par le nombre total de lignes. Le nombre moyen de lignes est calculé en prenant le nombre total de lignes (T) divisé par le nombre de valeurs distinctes (VD) dans la colonne. Ce qui donne :
(T / VD) / T
Qui équivaut à
1 / VD
Et en effet :
SELECT 1.00 / COUNT(DISTINCT ProductId))
FROM Production.TransactionHistoryretourne bien 0,0022675736961.
Plus la densité est faible, plus la sélectivité est élevée, et plus l'index est utile. La sélectivité maximale est offerte par un index unique, comme ici l'index ordonné unique sur la clé primaire de la table.
La densité de la colonne unique est donc 1 / VD, qui correspond logiquement à 1 / T, puisque le nombre de valeurs distinctes équivaut au nombre de lignes de la table.
SELECT 1.00 / COUNT(*)
FROM Production.TransactionHistoryretourne 0.0000088149996, ce qui représente une très basse densité, donc une sélectivité très élevée. Pour vérifier que nous obtenons bien la même valeur que la deuxième densité (ProductID, TransactionID), forçons la notation scientifique en retournant une donnée float :
SELECT CAST(1.00 as float) / COUNT(*)
FROM Production.TransactionHistoryqui donne une valeur approximative de 8,815E-06, CQFD.
Le couple ProductID + TransactionID ne peut être que d'une sélectivité maximale, puisqu'incluant une colonne unique, chaque ligne est donc unique, et sa densité est 1 / T.
III-C. Échantillonnage▲
| RANGE_HI_KEY | RANGE_ROWS | EQ_ROWS | DISTINCT_RANGE_ROWS | AVG_RANGE_ROWS |
|---|---|---|---|---|
| 1 | 0 | 45 | 0 | 1 |
| 3 | 45 | 307 | 1 | 45 |
| 316 | 45 | 307 | 1 | 45 |
| 319 | 144 | 118 | 2 | 72 |
| 322 | 218 | 108 | 2 | 109 |
| ... | ||||
| 748 | 0 | 386 | 0 | 1 |
| 779 | 37 | 771 | 7 | 5,285714 |
Avec les deux affichages précédents, l'optimiseur SQL sait quel est le nombre de lignes dans la table, et le nombre de valeurs distinctes dans la colonne indexée. Il lui faut maintenant pouvoir évaluer, pour une certaine valeur de colonne, quel sera le nombre approximatif de lignes concernées (combien ProductId = 760 concerne-t-il de lignes ?). Pour cela, il maintient un échantillonnage des valeurs établi selon un certain nombre de sauts (les steps que nous avons vus dans les informations de header), sous forme d'un tableau. Dans notre exemple, un tableau de 200 steps. SQL Server crée un maximum de 200 steps par statistiques. Détaillons la signification des colonnes :
| RANGE_HI_KEY | La valeur de colonne de l'échantillon, donc de la dernière ligne de l'ensemble échantillonné (le bucket) |
| RANGE_ROWS | Le nombre de lignes entre l'échantillon et l'échantillon précédent, ces deux échantillons non compris |
| EQ_ROWS | Nombre de lignes dans l'ensemble dont la valeur est égale à celle de l'échantillon |
| DISTINCT_RANGE_ROWS | Nombre de valeurs distinctes dans l'ensemble |
| AVG_RANGE_ROWS | Nombre moyen de lignes de l'ensemble ayant la même valeur, donc RANGE_ROWS / DISTINCT_RANGE_ROWS |
Nous voyons donc ici comment l'optimiseur a estimé le nombre de lignes retournées par la clause WHERE ProductId = 760 : il s'est positionné sur l'échantillon 779, puisque la valeur 760 est contenue dans l'ensemble échantillonné de cette ligne, et a retrouvé la valeur de AVG_RANGE_ROWS.
Dans le case de ProductId = 800, l'optimiseur a trouvé la ligne où le RANGE_HI_KEY = 800. Le nombre d'EQ_ROWS est 418.
Pourquoi l'optimiseur fait-il le choix de parcourir la table au lieu d'utiliser l'index ? Sachant qu'il aura à retourner 418 lignes, cela fait donc potentiellement un maximum de 418 pages de 8 ko en plus des pages de l'index à parcourir.
Nous savons, grâce à la requête suivante, combien de pages sont utilisées par chaque index :
SELECT o.name AS table_name,
p.index_id,
i.name AS index_name,
au.type_desc AS allocation_type,
au.data_pages, partition_number
FROM sys.allocation_units AS au
JOIN sys.partitions AS p ON au.container_id = p.partition_id
JOIN sys.objects AS o ON p.object_id = o.object_id
LEFT JOIN sys.indexes AS i ON p.index_id = i.index_id
AND i.object_id = p.object_id
WHERE o.name = N'TransactionHistory'
ORDER BY o.name, p.index_id| index_name | allocation_type | data_pages |
|---|---|---|
| PK_TransactionHistory_TransactionID | IN_ROW_DATA | 788 |
| IX_TransactionHistory_ProductID | IN_ROW_DATA | 155 |
| IX_TransactionHistory_ReferenceOrderID_ReferenceOrderLineID | IN_ROW_DATA | 211 |
Nous pouvons donc supposer qu'un scan de la table (donc de l'index ordonné) coûtera la lecture de 788 pages, donc 788 reads. Cela représente bien plus que 418 pages. Pourquoi choisir un scan ?
Analysons ce qui se passe réellement lorsque nous utilisons un plan ou un autre. Nous pouvons le découvrir en forçant l'optimiseur à utiliser l'index en ajoutant un index hint dans la requête :
SET STATISTICS IO ON
GO
SELECT *
FROM Production.TransactionHistory
WITH (INDEX = IX_TransactionHistory_ProductID)
WHERE ProductId = 800Voici les résultats de pages lues (reçues grâce à SET STATISTICS IO ON qui active le renvoi d'informations d'entrées/sorties), et le plan d'exécution utilisé :
Table 'TransactionHistory'.
Scan count 1, logical reads 1979, physical reads 3, read-ahead reads 744,
lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.Relançons ensuite la requête en laissant SQL Server choisir son plan :
SELECT *
FROM Production.TransactionHistory
WHERE ProductId = 800Résultat :
Table 'TransactionHistory'.
Scan count 1, logical reads 792, physical reads 0, read-ahead reads 44,
lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.Alors qu'en SQL Server 2000, l'utilisation de l'index aurait entraîné un bookmark lookup, c'est-à-dire une recherche à partir du pointeur présent dans le dernier niveau de l'index, SQL Server 2005 essaie autant que possible d'éviter le bookmark lookup. Le plan généré utilise donc une jointure entre les deux index : l'index non ordonné IX_TransactionHistory_ProductID est utilisé pour chercher les lignes correspondant au critère, et une jointure de type nested loop est utilisée pour parcourir l'index ordonné à chaque occurrence trouvée, pour extraire toutes les données de la ligne (SELECT *).
Cette jointure doit donc lire bien plus de pages que celles de l'index, puisqu'on doit aller chercher toutes les colonnes de la ligne. À chaque ligne trouvée, il faut parcourir l'index ordonné pour retrouver la page de données et en extraire la ligne. En l'occurrence cela entraîne la lecture de 1979 pages.
Nous avons vu que l'index ordonné utilise 788 pages. Le scan de cet index, selon les informations d'entrées/sorties, a coûté 792 lectures de page. D'où sortent les quatre pages supplémentaires ?
Selon la documentation de la vue sys.allocation_units dont la valeur 788 est tirée, la colonne data_pages exclut les pages internes de l'index et les pages de gestion d'allocation (IAM). Les quatre pages supplémentaires sont donc probablement ces pages internes. Nous pouvons le vérifier rapidement grâce à une commande DBCC non documentée qui liste les pages d'un index : DBCC IND
DBCC IND (AdventureWorks, 'Production.TransactionHistory', 1)où le troisième paramètre est l'id de l'index. L'index ordonnée prend toujours l'id 1.
Le résultat de cette commande nous donne 792 pages, donc 788 sont des pages de données, plus une page d'IAM (PageType = 10) et trois pages internes (PageType = 2). Voilà pour le mystère.
IV. Résumés de chaîne▲
Les résumés de chaîne (string summary) sont une addition aux statistiques dans SQL Server 2005. Comme vous l'avez vu dans le header retourné par DBCC SHOW_STATISTICS, la valeur de String Index indique si les statistiques pour cette clé de l'index contiennent des résumés de chaîne. Il s'agit d'un échantillonnage à l'intérieur d'une colonne de type chaîne de caractères (un varchar par exemple), qui permet à l'optimiseur de décider d'utiliser un index lors d'une recherche avec un opérateur LIKE. Ces résumés de chaîne ne couvrent que 80 caractères de la donnée (les 40 premiers et 40 derniers si la chaîne est plus longue). Vous avez un exemple de test de cette nouvelle fonctionnalité dans AdventureWorks dans cette entrée de blog : Lara's Blog.
Dans SQL Server 2000, un index sur une colonne varchar n'était utilisé dans le cas d'un LIKE que lorsque le début de la chaîne était connu, ou selon un algorithme d'estimation nettement moins précis que les résumés de chaînes.
V. Gérer les statistiques▲
V-A. Consultation▲
Nous pouvons vérifier la présence de statistique de plusieurs manières :
- sp_helpstats est l'ancienne méthode d'obtention des statistiques. Ne l'utilisez plus et préférez les vues de catalogues ci-dessous :
- sys.stats : liste des statistiques présentes dans la base de données ;
- sys.stats_columns : colonnes présentes pour chaque statistique
SELECT *
FROM sys.stats s
JOIN sys.stats_columns sc ON s.object_id = sc.object_id
AND s.stats_id = sc.stats_id
JOIN sys.columns c ON s.object_id = c.object_id
AND sc.column_id = c.column_id- STATS_DATE() : vous pouvez récupérer la date de dernière mise à jour des statistiques en utilisant la nouvelle fonction STATS_DATE() de SQL Server 2005, à laquelle vous passez un id de table et un id d'index
SELECT OBJECT_NAME(i.object_id) AS table_name,
i.name AS index_name,
STATS_DATE(i.object_id, i.index_id)
FROM sys.indexes AS i
WHERE OBJECT_NAME(i.object_id) = N'TransactionHistory'- DBCC SHOW_STATISTICS : comme nous l'avons déjà vu, DBCC SHOW_STATISTICS affiche les détails d'un jeu de statistiques.
V-B. Création▲
Les statistiques sur les index sont créées automatiquement, sans possibilité de désactivation : un index sans statistique serait inutilisable.
Les statistiques sur les colonnes non indexées peuvent être créées manuellement ou automatiquement.
Par défaut, les bases de données sont créées avec l'option AUTO_CREATE_STATISTICS à ON, c'est-à-dire que les statistiques dont l'optimiseur de requêtes a besoin pour générer son plan d'exécution seront générées à la volée. Certes, il y aura un ralentissement du service de la requête dû à la création des statistiques, mais cela ne se produira que la première fois, et potentiellement ce ralentissement sera moindre que celui induit par un plan d'exécution mal évalué.
Cette fonctionnalité, de création et mise à jour automatique des statistiques par SQL Server, est appelée Auto Stats.
Pour créer manuellement des statistiques sur une ou plusieurs colonnes, vous pouvez utiliser la commande CREATE STATISTICS :
CREATE STATISTICS statistics_name
ON { table | view } ( column [ ,...n ] )
[ WITH
[ [ FULLSCAN
| SAMPLE number { PERCENT | ROWS }
[ NORECOMPUTE ]
] ;Il peut être intéressant par exemple de créer manuellement des statistiques sur une combinaison de colonnes pour améliorer l'estimation du plan d'une requête dont la clause WHERE filtre sur ces colonnes.
WITH FULLSCAN vous permet d'indiquer que toutes les valeurs doivent être parcourues. Sur les tables volumineuses, l'échantillonnage ne se fait pas sur toutes les valeurs, les statistiques seront donc moins précises. En indiquant WITH FULLSCAN (ou WITH SAMPLE 100 PERCENT, qui est équivalent), vous forcez SQL Server à prendre en compte toutes les lignes. Pour les tables de taille moyenne, l'échantillonnage se fait de toute manière sur toutes les valeurs. SQL Server s'assure un minimum de 8 MB de données échantillonnées (1024 pages ou plus), ou la taille de la table si elle pèse moins.
À l'inverse, vous pouvez demander un échantillonnage moins précis avec l'option WITH SAMPLE. Notez que si SQL Server considère que votre sampling n'est pas suffisamment élevé pour générer des statistiques utiles, il corrige lui-même la valeur à la hausse.
Avec NORECOMPUTE, vous forcez SQL Server à ne jamais mettre à jour automatiquement ces statistiques. Ne l'utilisez que si vous savez ce que vous faites.
Vous pouvez supprimer des statistiques avec l'instruction DROP STATISTICS. Vous ne devriez normalement jamais avoir à faire cela.
Si à la suite de cet article, vous êtes tombé amoureux des statistiques, vous pouvez, grâce à la procédure sp_createstats, créer en une seule fois, des statistiques pour toutes les colonnes de toutes les tables de votre base.
Cela doit être une charmante expérience que je n'ai jamais tentée. Si vous voulez réaliser des optimisations poussées de votre système, vous pouvez vous y lancer. Cela vous permettra d'éviter le temps d'attente à la première exécution d'une requête qui va nécessiter la création de statistiques. Dans la plupart des cas, la fonctionnalité Auto Stats vous suffira amplement.
V-C. Mise à jour▲
La mise à jour des statistiques est importante. Pour reprendre notre exemple, supposons qu'avant de partir pour Courtrai, vous en parliez avec votre grand-père qui vous annonce qu'il connaît bien Courtrai pour y avoir passé ses vacances d'été pendant plusieurs années avec sa famille lorsqu'il était enfant. Par politesse vous évitez de commenter les choix de destination de vacances de vos arrière-grands-parents, d'autant plus qu'il se souvient d'avoir eu en son temps un plan détaillé de la ville. Intéressant, cela vous permettrait de vous faire une idée plus précise de vos déplacements. Après quelques recherches au grenier, il vous ressort un vieux plan très jauni, qui date de 1933. Pensez-vous réellement qu'il va vous être très utile, sachant que la ville a été très endommagée par les bombardements de 1944, et qu'une grande partie de celle-ci a été reconstruite après la guerre ?
Le contenu de votre table évolue, et vous ne pouvez baser ad vitam aeternam l'évaluation de la sélectivité d'une colonne sur les statistiques telles qu'elles ont été créées. Cette mise à jour doit se faire régulièrement et prendre en compte les larges modifications de données. Comme la création, elle peut se déclencher automatiquement ou manuellement.
Automatiquement avec l'option de base de données AUTO UPDATE STATISTICS, qu'il est vivement recommandé de laisser à ON, telle qu'elle est par défaut.
SELECT DATABASEPROPERTYEX('IsAutoUpdateStatistics') -- pour consulter la valeur actuelle
ALTER DATABASE AdventureWorks SET AUTO_UPDATE_STATISTICS [ON|OFF] -- pour modifier la valeurEn SQL Server 2000, la mise à jour automatique des statistiques était déclenchée par un nombre de modifications de lignes de la table. Chaque fois qu'un INSERT, DELETE ou une modification de colonne indexée était réalisée, la valeur de la colonne rowmodctr de la table sysindexes était incrémentée. Pour que la mise à jour des statistiques soit décidée, il fallait que la valeur de rowmodctr soit au moins 500. Si cela vous intéresse, vous trouverez une explication plus détaillée de ce mécanisme dans le document de la base de connaissances Microsoft 195565, listé en bibliographie.
Avec SQL Server 2005, ce seuil (threshold) est géré plus finement. La colonne rowmodctr est toujours maintenue mais on ne peut plus considérer sa valeur comme exacte. En effet, SQL Server maintient des compteurs de modifications pour chaque colonne, dans un enregistrement nommé colmodctr présent pour chaque colonne de statistique. Cependant, à ma connaissance, cette colonne n'est pas visible. Vous pouvez toujours vous baser sur la valeur de rowmodctr pour déterminer si vous pouvez mettre à jour les statistiques sur une colonne, ou si la mise à jour automatique va se déclencher bientôt, car les développeurs ont fait en sorte que sa valeur soit " raisonnablement " proche de ce qu'elle donnait dans les versions suivantes.
V-C-1. sp_autostats▲
Vous pouvez activer ou désactiver la mise à jour automatique des statistiques sur un index, une table ou des statistiques, en utilisant la procédure stockée sp_autostats :
sp_autostats [@tblname =] 'table_name'
[, [@flagc =] 'stats_flag']
[, [@indname =] 'index_name']Le paramètre @flagc peut être indiqué à ON pour activer, OFF pour désactiver, NULL pour afficher l'état actuel.
V-C-2. sp_updatestats▲
sp_updatestats met à jour les statistiques de toutes les tables de la base courante, mais seulement celles qui ont dépassé le seuil d'obsolescence déterminé par rowmodctr (contrairement à SQL Server 2000 qui met à jour toutes les statistiques). Cela vous permet de lancer une mise à jour des statistiques de façon contrôlée, durant des périodes creuses, afin d'éviter d'éventuels problèmes de performances dus à la mise à jour automatique, dont nous allons parler dans la section suivante.
V-C-3. Mise à jour et performances▲
Nous avons vu que les mises à jour de statistiques sont indispensables à la bonne performance des requêtes, et que leur maintenance est nécessaire pour assurer une bonne qualité à travers le temps. Mais, quand cette opération se déclenche-t-elle ?
Tout comme la création automatique, elle se produit au besoin, c'est-à-dire au moment où une requête va s'exécuter et pour laquelle ces statistiques sont utiles, aussi bien dans le cas d'une requête ad hoc (c'est-à-dire d'une requête écrite une fois pour un besoin particulier), que d'une procédure stockée. Si le seuil de modification de la table est atteint, il va d'abord lancer une mise à jour des statistiques nécessaires, ensuite générer son plan d'exécution. Cela peut évidemment provoquer une latence à l'exécution de la requête. Pour les plans d'exécution déjà dans le cache (le cache de plans d'exécution, ou plan cache, qui contient des plans réutilisables pour des requêtes répétitives, et notamment les procédures stockées), la phase d'exécution inclut une vérification des statistiques, un update éventuel de celles-ci, puis une recompilation, ce qui dans certains cas peut se révéler encore plus lourd.
Cela pose rarement un problème, mais si vous êtes dans le cas où cela affecte vos performances, vous avez quelques solutions à votre disposition :
- une nouvelle option de SQL Server 2005 : AUTO_UPDATE_STATISTICS_ASYNC, vous permet de réaliser une mise à jour des statistiques de façon asynchrone. Cela veut dire que lorsque le moteur SQL décide de mettre à jour ses statistiques, il n'attend pas la fin de cette opération pour exécuter la requête qui déclenche cette mise à jour. Elle s'exécute donc plus vite, mais pas forcément plus rapidement, car avec un plan d'exécution potentiellement obsolète. Les exécutions suivantes profiteront des statistiques rafraîchies. En temps normal, cette option n'est pas conseillée ;
- vous pouvez mettre à jour manuellement vos statistiques durant vos fenêtres d'administration, en utilisant par exemple sp_updatestats, ou une tâche d'un plan de maintenance.
V-C-4. Plan de maintenance▲
Dans la boîte du plan de maintenance, l'outil d'optimisation et de sauvegarde de vos bases, vous disposez d'une tâche pour planifier aisément la mise à jour de vos statistiques. Vous pouvez découvrir dans les deux copies d'écran ci-dessous les options à votre disposition.
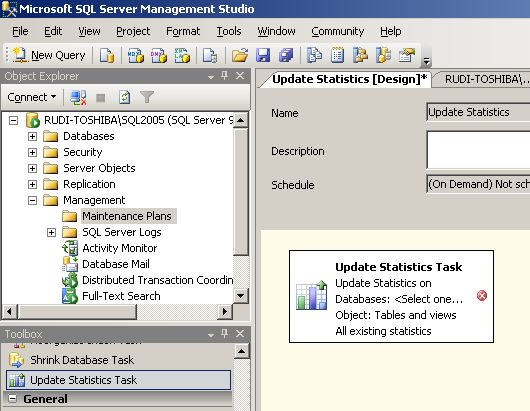
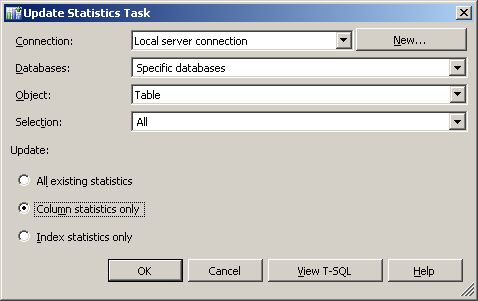
VI. Étudier leur comportement▲
Pour étudier la vie des statistiques, pas besoin de rester des journées entières caché dans une cabane au milieu des roseaux, la caméra à la main.
Votre meilleur ami, dans ce cas comme dans tous les autres, est le profiler (générateur de profils), l'outil de la palette SQL Server qui vous permet de tracer tous les événements (ou presque) déclenchés par le serveur SQL.
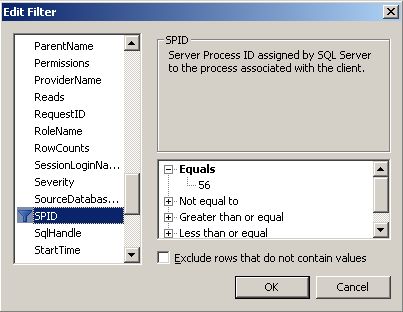
Dans les exemples que nous allons prendre, nous allons utiliser le profiler en limitant la trace à nos propres opérations. Pour cela, le moyen le plus simple est de filtrer la trace par notre SPID (l'identificateur du processus/de la connexion dans SQL Server).
Vous pouvez identifier votre SPID soit par la variable @@SPID :
SELECT @@SPIDsoit directement dans SSMS (SQL Server Management Studio), dans la barre d'état, comme encadré dans la copie d'écran ci-dessous :

Nous voyons ici que notre SPID est le 56. Ouvrons maintenant le profiler : dans le menu Démarrer / Programs / Microsoft SQL Server 2005 / Performance Tools / SQL Server Profiler. Nous créons une nouvelle trace, et dans l'onglet Events Selection de la configuration de la trace, on clique sur le bouton Column Filters.... Dans la liste des colonnes, nous cherchons SPID. Nous entrons le numéro du SPID comme valeur Equal, comme indiqué dans la copie d'écran :
Ensuite, après avoir fermé cette fenêtre par OK, nous activons la case Show all events, et ajoutons les événements :
- Errors and Warnings / Missing Column Statistics ;
- Performance / Auto Stats ;
- TSQL / SQL:StmtStarting ;
- TSQL / SQL:StmtCompleted ;
- TSQL / SQL:StmtRecompile.
Nous ajoutons également quelques colonnes en activant Show All Columns, et en sélectionnant ObjectId et IndexId pour l'événement Auto Stats, et EventSubClass pour le SQL:StmtRecompile.
Nous sommes prêts à lancer la trace.
Nous allons nous concentrer sur la table Person.Contact, de la base de données d'exemple de Microsoft : AdventureWorks.
Tout d'abord, vérifions quelles sont les statistiques présentes sur cette table, avec la requête suivante :
SELECT * FROM sys.stats WHERE object_id = OBJECT_ID('Person.Contact')
Nous voyons qu'il n'y a pour l'instant que des statistiques correspondant à des index.
Exécutons une requête qui filtre les données sur une colonne non présente dans un index :
SELECT *
FROM Person.Contact
WHERE FirstName = 'Lily'Il n'y a pas de prénom qui correspond à Lily dans les données de la table, le résultat revient donc vide.
Des statistiques ont-elles été créées ? Nous allons voir dans le profiler :
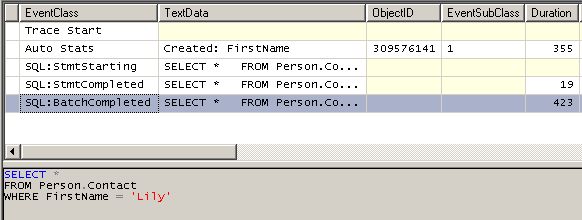
Nous voyons une ligne d'exécution de la fonctionnalité Auto Stats : des statistiques ont été créées sur notre colonne FirstName. On s'y attendait un peu… La génération des statistiques a duré 355 millisecondes.
Notons également l'objectId. Vérifions qu'il s'agit bien de notre table :
SELECT OBJECT_ID('Person.Contact')retourne 309576141. CQFD.
Donc, un nouveau jeu de statistiques doit être présent dans sys.stats. Vérifions :
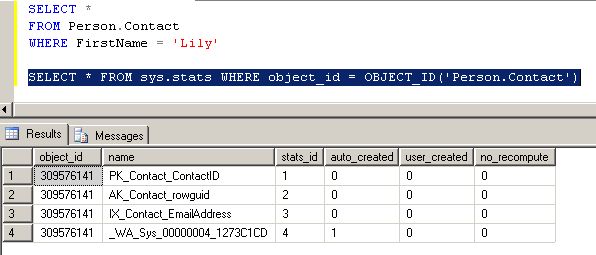
Parfait ! Nous voyons l'ObjectId, le nom des statistiques qui commence toujours par _WA_Sys pour les colonnes non indexées, et le flag auto_created à 1.
Que se passe-t-il dans la table système sysindexes ? Jetons un œil à travers la vue qui y donne accès :
SELECT name, status, root, indid, rowcnt, rowmodctr
FROM sys.sysindexes WHERE id = OBJECT_ID('Person.Contact')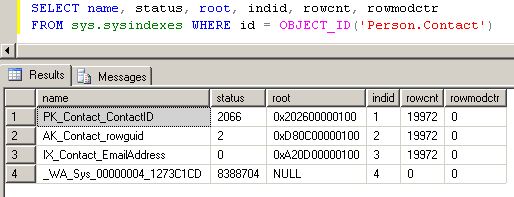
Nous retrouvons bien nos statistiques, le pointeur sur la page racine (root) de l'index, qui est ici naturellement à NULL, puisqu'il ne s'agit pas d'un index, le rowcnt à 0 pour la même raison, et le rowmodctr lui aussi à 0, puisqu'aucun changement n'a été effectué dans les données.
À ce propos, que va-t-il se passer si nous changeons massivement les valeurs de cette colonne ? Faisons le test, en conservant le prénom original dans une colonne de sauvegarde :
ALTER TABLE Person.Contact
ADD FirstNameSave Name - type défini par l'utilisateur dans la base AdventureWorks
UPDATE Person.Contact
SET FirstNameSave = FirstName
UPDATE Person.Contact
SET FirstName = 'Lily'Revérifions sysindexes :
SELECT name, status, root, indid, rowcnt, rowmodctr
FROM sys.sysindexes WHERE id = OBJECT_ID('Person.Contact')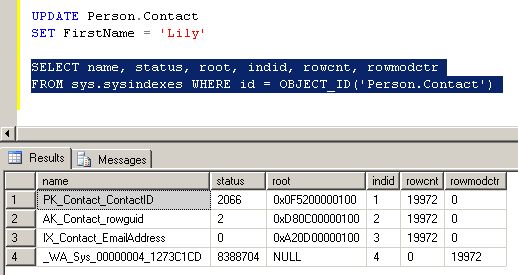
rowmodctr contient maintenant 19 972, c'est bien le nombre de lignes de notre table : elles ont toutes été modifiées.
Relançons notre SELECT, et voyons si les statistiques vont être mises à jour…
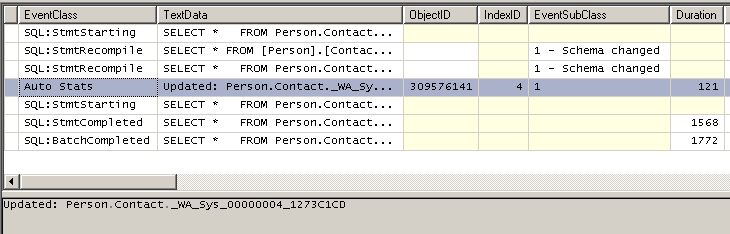
Bingo ! Le profiler nous montre en détail ce qui se passe : Le SELECT, dont le plan d'exécution a été conservé dans le cache, est exécuté. Mais en comparant son seuil de recompilation contre rowmodctr, le moteur SQL s'aperçoit que le plan n'est plus optimal. Il prend donc la décision de le recompiler, recalcule les statistiques, et relance l'exécution. La mise à jour des statistiques a duré 121 millisecondes.
Voyons ensuite ce qui se passe lorsque nous désactivons la mise à jour automatique des statistiques :
ALTER DATABASE AdventureWorks SET AUTO_UPDATE_STATISTICS OFF
UPDATE Person.Contact
SET FirstName = FirstNameSave
SELECT *
FROM Person.Contact
WHERE FirstName = 'Lily'
Cette fois-ci, comme on peut s'y attendre, plus d'Auto Stats, et plus de recompilation.
Que se passe-t-il maintenant lorsque nous désactivons la création automatique des statistiques, et que nous effectuons une requête sur une colonne qui en est dépourvue, par exemple LastName ?
ALTER DATABASE AdventureWorks SET AUTO_CREATE_STATISTICS OFF
SELECT *
FROM Person.Contact
WHERE LastName = 'Smith'Regardons d'abord quel est le plan d'exécution estimé, en sélectionnant la requête et en pressant CTRL+L :
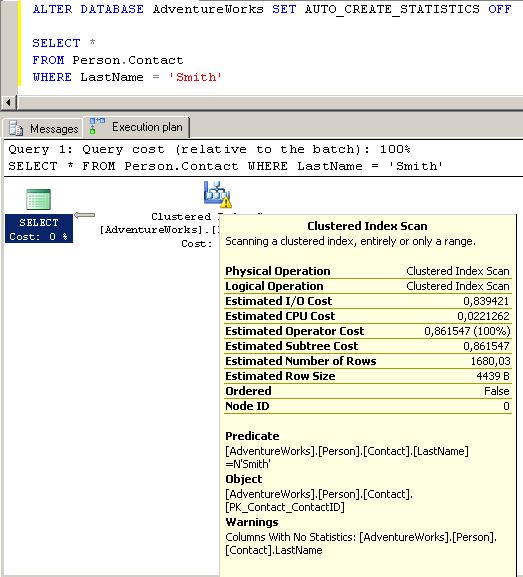
Nous voyons que l'optimiseur regrette l'absence de statistiques sur LastName, et nous en avertit (le point d'exclamation sur l'étape de scan). En laissant la souris sur l'étape du scan de l'index ordonné, on voit en bas le détail du warning.
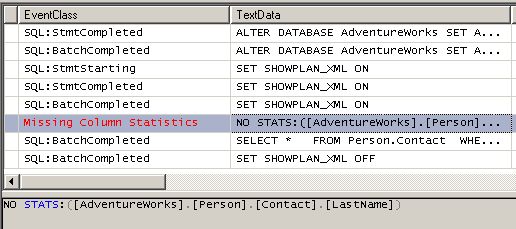
De même, le problème nous est signalé par la trace du profiler :
Une dernière question nous hante : est-ce que ce warning est reflété dans les nouvelles vues de gestion dynamiques de l'optimiseur ? Rappelons qu'une nouveauté de SQL Server 2005 est la mise à disposition de différentes informations et statistiques dans des vues dites de gestion dynamique (dynamic management), qui affichent des valeurs glanées depuis le lancement du service, et qui concernent notamment les index. Trois vues sont utiles à ce titre :
- sys.dm_db_missing_index_groups ;
- sys.dm_db_missing_index_group_stats ;
- sys.dm_db_missing_index_details ;
qui conservent les informations d'index manquant qui auraient été utiles à l'optimiseur pour l'exécution d'une requête. Jetons un œil :
SELECT equality_columns, inequality_columns, statement
FROM sys.dm_db_missing_index_details
WHERE database_id = DB_ID() AND
object_id = OBJECT_ID('Person.Contact')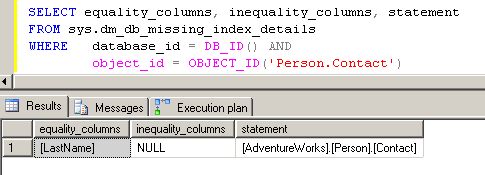
Bonne nouvelle ! Un autre outil d'optimisation est à notre disposition dans ces vues dynamiques.
VII. Conclusion▲
Intéressant, non ?
VIII. Bibliographie▲
- Kalen Delaney, Inside SQL Server 2005 : The Storage Engine, Microsoft Press
- Itzik Ben-Gan and al, Inside SQL Server 2005 : T-SQL Programming, Microsoft Press
- Ken Henderson, The Guru's Guide to SQL Server Architecture and Internals, Addison Wesley
- Sajal Dam, SQL Server Query Performance Tuning Distilled, Curling Stone (ancienne édition)
- http://www.microsoft.com/technet/prodtechnol/sql/2005/qrystats.mspx
- Statistical maintenance functionality (autostats) in SQL Server (pour SQL Server 2000)
- sys.sysindexes
- about the missing index feature
- recompilations, avec explication sur les recompilations dues aux statistiques
- Élémentsd'optimisation et de tuning pour SQL Server 2000 et 2005